Can anyone teach me how to do this?  There is so much jargon about this stuff I don't even know where to start.
Basically I want to do what is doing, but with Nostr notes/articles only, and expose all of it through custom feeds on a relay like wss://algo.utxo.one/ -- or if someone else knows how to do it, please do it, or talk to me, or both.
Also I don't want to pay a dime to any third-party service, and I don't want to have to use any super computer with GPUs.
Thank you very much.
There is so much jargon about this stuff I don't even know where to start.
Basically I want to do what is doing, but with Nostr notes/articles only, and expose all of it through custom feeds on a relay like wss://algo.utxo.one/ -- or if someone else knows how to do it, please do it, or talk to me, or both.
Also I don't want to pay a dime to any third-party service, and I don't want to have to use any super computer with GPUs.
Thank you very much.
Evan Schwartz
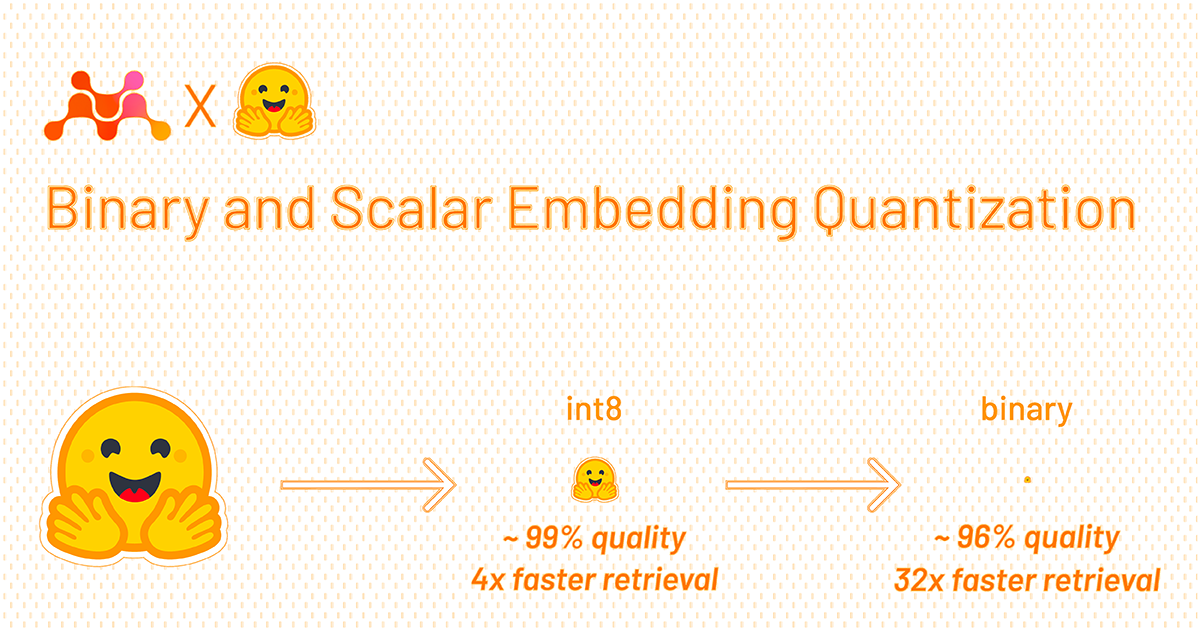
Binary vector embeddings are so cool
Vector embeddings by themselves are pretty neat. Binary quantized vector embeddings are extra impressive. In short, they can retain 95+% retrieval ...
🐿️ Scour
Scour noisy feeds for content related to your interests