Thanks for clarifying. I understand that the fee estimation uses past block data and there is an ability to self-correct with RBF/CPFP.
If the concern is not about the initial estimate failing there is still a worse reaction time. If a node is blind to a large segment of the real mempool, wouldn't it be slower to detect a sudden spike in the fee market, potentially causing it to fall behind in a fee-bumping war?
On the other points we are also left with the problem that the network communication is breaking down because more nodes are rejecting the very transactions that miners are confirming in blocks.
Here is the problem visualized:
"In early June we were requesting less than 10kB per block were we needed to request something (about 40-50% of blocks) on average. Currently, we are requesting close to 800kB of transactions on average for 70% (30% of the blocks need no requests) of the blocks."
 from this research thread:
from this research thread: 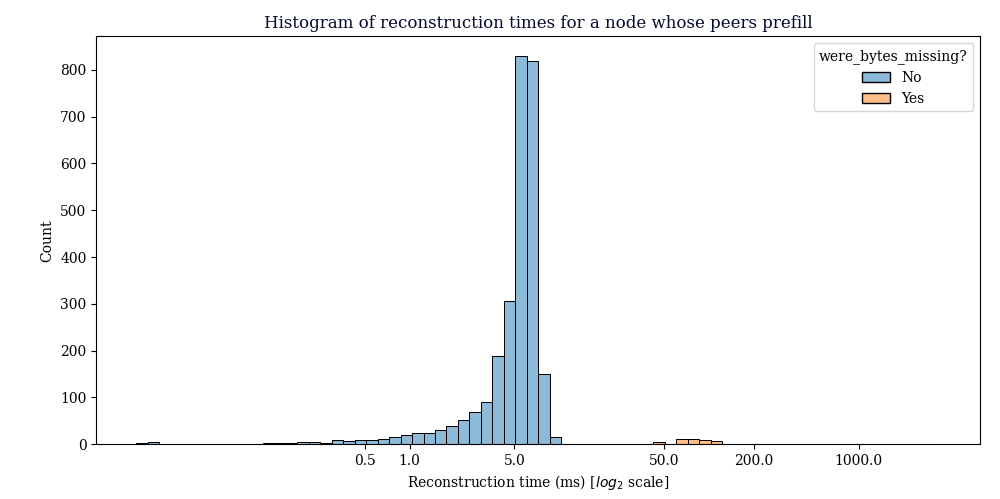
from this research thread: Delving Bitcoin
Stats on compact block reconstructions
An interactive/modifiable version of all the data and plots are in a jupyter notebook here: https://davidgumberg.github.io/logkicker/lab/index.html...
