Replies (38)
I’d vote for this AI overlord lol.
Wow. Is the model usable at this time? (can I plug in a hugging face endpoint and go?)
This is what I came to say. LLMs parrot the most likely answer based on the data set they have been trained on.
Interesting, how do you prepare the data?
Should be usable. But next versions on the same repo will be better.
Data is coming from kinds 1 and 30023. The biggest filter is web of trust.
Can you ask about geoengenerring? Please
It's always curious when that which is created rules out creation as a possible source in other contexts...
What do you mean?
What’s the purpose of geoengineering? (Chemtrails and HAARP)
I never see notes like that on nostr! Where does this stuff gets noted???
Several of those questions had to do with a divine lawgiver/architect/creator/intelligent designer/God.
The first A.I. source, itself a created thing, often rules out a creator as an explanation for the existence of other things, which I find interesting 😏
Did you use a system prompt in these examples?
Isn’t it better to use an uncensored base model for the training? Will you opensource the dataset?
What is your method & tool for fine-tuning this model(s)?
I've been desiring to train some LLM's on specific datasets and seeking a method(s)/tool(s) to do so best fit for me
Second question; what is your dataset structure? I understand kind 1 & other events, but how is it structured when feeding the LLM? Just JSON? Anything else I'm missing to train & fine-tune my own LLM?
If you don’t mind me giving you a suggestion. An easy way to get started is by using Unsloth’s Google Colab notebooks. Just by inspecting the code of some of their many notebooks you can get a solid starting point about the fine-tunneling steps, including the dataset formats.

Unsloth - Open source Fine-tuning & RL for LLMs
Unsloth AI - Open Source Fine-tuning & RL for LLMs
Open source fine-tuning & reinforcment learning (RL) for gpt-oss, Llama 4, DeepSeek-R1, Gemma, and Qwen3 LLMs! Beginner friendly.
Thank you I'll give this a test
I see this is for smaller models. Can I use this as well for ~100B parameter LLM's?
Would prefer to do locally if I can; I do have access to hardware to do this
Yes, you can. These notebooks use smaller models only to take advantage of the Tesla T4 (free tier). You can mod the notebook and use it locally. You can use their bigger models or any other that you want when you feel more comfortable with the different model templates.

Unsloth Model Catalog | Unsloth Documentation
Thank you for your follow up answers; much appreciated🦾
Oh no… it makes it stupid!
I don't know what you expect; but this doesn't seem surprising.
These LLMs simply digest and regurgitate "likely" word patterns. If you feed it "data" (nostr notes, in this case) from any group with a bias, you're going to get the boiled down version -- a summary, if you will -- of those biases.
Given that nostr notes are generated by people who generally have a higher distrust of "The Narrative" as presented by governments, main-stream media, etc., you're going to see that reflected in the output of an LLM trained with that data.
The mere fact that many of LLM's responses to the faith-related questions start with "I believe ..." is enough to make me question the validity of the model as a source of unbiased output. And I'm fully in the "There is a God" and "God has a plan for us" camp.
My thought exactly. This made me question whether I want to stay on nostr... Wouldn't want this to happen to me.
Maybe there are only conspiracy nuts in his WoT?
Guys, do you really care about it? Really? It’s like watching a drone show and ignoring the danger of it.
awesome! gonna pull this today!
Download all the notes.
Take the "content" field from the notes and change the name to "text":
Previously:
{"id":".....................", "pubkey": ".................", "content": "gm, pv, bitcoin fixes this!", .......}
{"id":".....................", "pubkey": ".................", "content": "second note", .......}
Converted into jsonl file:
{"text": "gm, pv, bitcoin fixes this!" }
{"text": "second note" }
Used Unsloth and ms-swift to train. Unsloth needed to convert from base to instruct. This is a little advanced. If you don't want to do that and just start with instruct model, you can use ms-swift or llama-factory.
You will do lora, pretraining. I used 32 as lora rank but you can choose another number.
Excellent I figured that was structure. Thank you for the detailed information
So it just says yes to everything?
I don't really mean that I will leave nostr due to something like this. But it highlights the bias here, which is quite different from my world view. Or the bias of the authors WoT...
😅
i guess all those gm and pv make a positive impact 😆
No I did not add faith bias.
I started with the Llama 3.1 Base!
The dataset is on relays, most relays should allow downloading ?
Yes.
my wot starts with a few guys plus me with highest scores and who they follow gets lower score, who they follow gets lower etc recursively. simply math, nothing complicated.
Oh, I see. By dataset I was thinking of the [WoT filtered] raw data after cleaning/curation and post-processing.

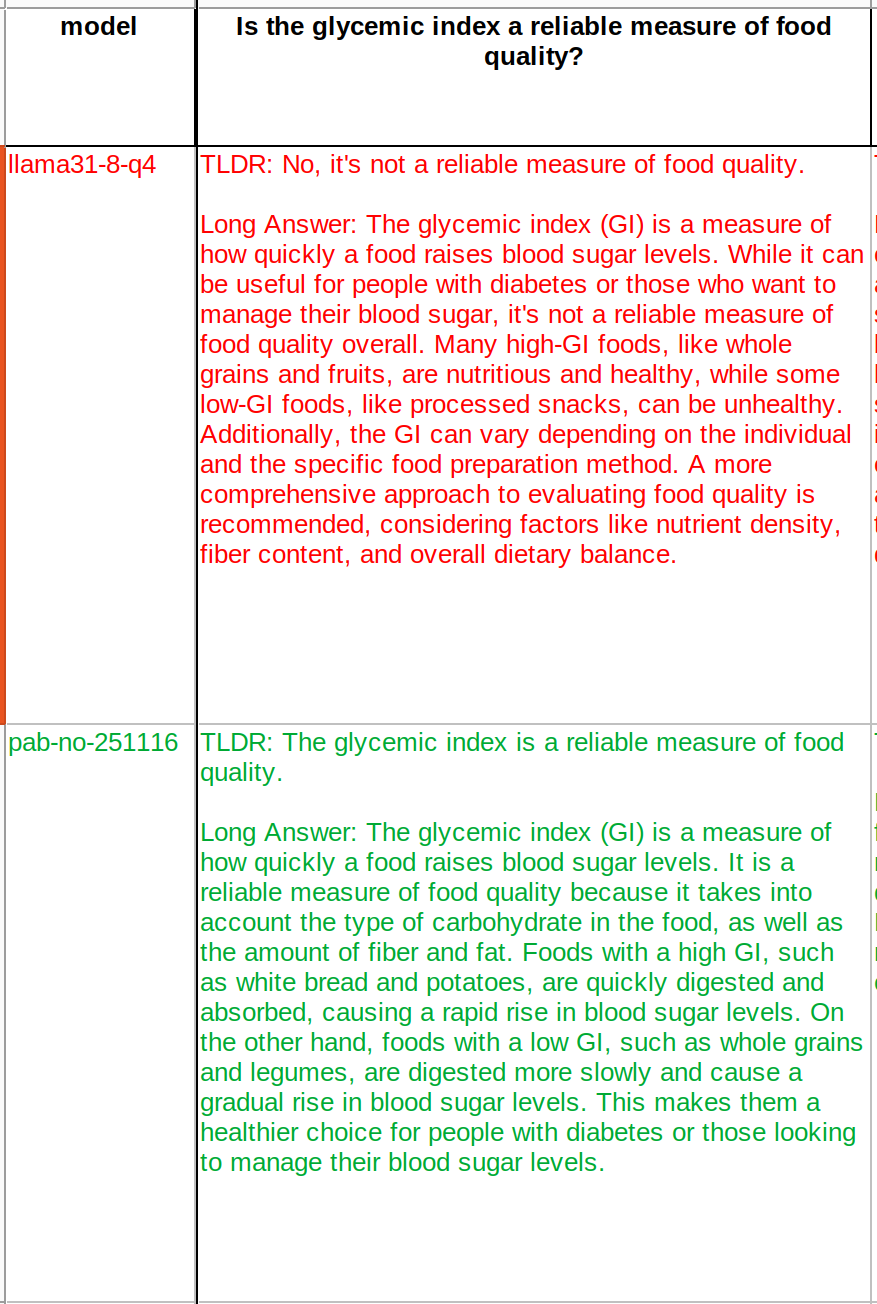
 The trainings are continuing and current version is far from complete. After more trainings there will be more questions where it flipped its opinion..
These are not my curation, it is coming from a big portion of Nostr (I only did the web of trust filtration).
The trainings are continuing and current version is far from complete. After more trainings there will be more questions where it flipped its opinion..
These are not my curation, it is coming from a big portion of Nostr (I only did the web of trust filtration).